
Anti-Design Pattern in Machine Learning - The big ball of mud Vs RecSys
Anti pattens exists in machine learning architecture as well like a monster eating your business value. I dicuss the "the big mud of ball" anti-pattern here along with a solution using 2x2 from RecSys

Anti-Design Pattern aka Monsters in Machine Learning
The big ball of mud:
In my two decades of work involving enterprise IT and now in Start-ups, I have seen anti-patterns time and again. This is not limited to IT systems but also in machine learning architecture that I have seen for customers that I have consulted for.

I would like to treat anti-patterns as “monsters” which eats your business value that you deliver for your business and customer.
Like money, anti-patterns compound with time. So it is critical to spot them and work towards best practises in design patterns.
Let’s me recap Anti-pattern in architecture for you, so that we have a common page:
An anti-pattern in software architecture refers to a common solution that appears to be helpful, but in reality, it is suboptimal or counterproductive. It's a design or implementation practice that may seem intuitive but can lead to inefficiencies, errors, or other negative consequences. Anti-patterns have business impacted when compounded over time.
In terms of its impact on business, anti-patterns in software architecture have several detrimental effects:
Reduced Performance: Anti-patterns can lead to inefficient code, causing applications to run slowly and impacting user experience. This can result in decreased customer satisfaction, poor user experience and engagement. This impacts top line for the customer in the long run.
Increased Maintenance Costs: Architectural anti-patterns can make codebases difficult to maintain and debug. This increases the time and effort required for ongoing maintenance, leading to higher costs for the business. This impacts the TOTEX (CAPEX + OPEX = TOTEX) of the project or the life cycle cost.
Scalability Issues: Anti-patterns may hinder the ability of software systems to scale effectively. This can limit the company's capacity to handle increased user loads or growth in the future.

Security Vulnerabilities: Some anti-patterns can introduce security vulnerabilities, making the software more susceptible to breaches and attacks. This can lead to data breaches, loss of sensitive information, and damage to the company's reputation.
Longer Development Cycles: Anti-patterns often result in complex and convoluted code. This can extend the development cycle, delaying the release of new features or products and affecting time-to-market.
Resource Wastage: Inefficient practices can lead to unnecessary resource consumption, such as CPU, memory, or storage. This can increase operational costs and reduce the overall efficiency of the software.
Lack of Agility: Anti-patterns can hinder the ability to make changes or adapt to new requirements quickly. This lack of agility can limit the company's ability to respond to market changes and innovations.
Negative User Experience: Ultimately, anti-patterns can lead to a poor user experience, causing frustration and dissatisfaction among customers. This can result in decreased customer retention and brand loyalty.
In machine learning context I have seen many such anti-patterns and here in this article I am talking of one such anti-pattern called as “Big ball of mud” anti-pattern.
In the context of software architecture, "big ball of mud" refers to the disorganization, complexity, and lack of structure within the architecture of a machine learning system. It represents a state where the components and modules of the system are tightly coupled, making it challenging to understand, maintain, and extend the system.
Wait, does it sound like a monolithic architecture? It does have a relation but both are not same.
Monolithic architecture vs Mud of ball anti-pattern:
The "Big Ball of Mud" anti-pattern highlights the lack of organization and structure in a system, whereas the concept of a "Monolithic Architecture" focuses on the integration of all components within a single codebase. Both concepts emphasize the importance of modularization, clear design, and maintainability in software development.
The "Big Ball of Mud" anti-pattern refers to a situation where a software system lacks a clear structure or organization.
It often arises as the result of incremental changes, lack of architectural planning, and a focus on short-term goals without considering long-term maintainability. This can lead to tangled, interconnected components that are hard to understand and modify.

On the other hand, a "Monolithic Architecture" refers to a specific type of software architecture where all the components of an application are tightly integrated into a single codebase and run as a single executable.
This can lead to challenges in scalability, deployment, and maintenance, especially as the application grows larger and more complex.
I consult for enterprises, and I have found the "mud" monsters in machine learning architecture as well. In what I have seen, the "mud" (from now on, I am calling the big ball of mud as ‘mud’) in this anti-pattern can manifest in enterprise in various ways:
Lack of Modularity: The ML system lacks a clear separation of concerns and a modular design. Components responsible for data pre-processing, feature engineering, model training, and inference are tightly intertwined, making it difficult to modify or update specific parts without impacting the entire system.
There is no standardized approach for managing models as they scale leading to fragmentation, difficulty in performance tracking, and challenges in updating or improving the models as data drifts or grows.
Mixing of Concerns: Business logic, data processing, and machine learning code are intertwined, leading to code duplication, increased complexity, and decreased code maintainability. The responsibilities of different components are not well defined, resulting in a convoluted system structure. Pipeline started as an approach to solve this issue but scaling with pipelines can be a nightmare as well.
Lack of Clear Architecture: The ML system lacks clear architectural boundaries, layering, or separation of concerns. There is no well-defined structure for organizing components, leading to dependencies and entangled relationships between different parts of the system.
“Plese consider sharing this article if you are finding it useful”
Learning from recomender systems/RecSys:
Imagine a machine learning system developed for personalized product recommendations on an e-commerce platform. Over time, as the system evolves, the architecture becomes disorganized and tangled, just as explained above for the big ball of mud monster:
Monolithic Recommendation Engine: The entire recommendation engine, including data ingestion, pre-processing, feature extraction, model training, and inference, is implemented within a single monolithic codebase. This results in a complex and tightly coupled system that is challenging to maintain and extend.
Mixing Business Rules: Business rules, such as pricing logic, inventory management, and user segmentation, are intermingled with the recommendation engine code. This leads to code duplication, increased complexity, and decreased maintainability.
Ad-hoc Data Processing: Data processing, such as user interactions, purchase history, and product metadata, is scattered across various parts of the system without a cohesive structure. This makes it difficult to track data dependencies and ensure consistent data quality.
Lack of Modularity: The system lacks modular components for different stages of the recommendation process, such as collaborative filtering, content-based filtering, and hybrid models. This hampers reusability, scalability, and the ability to experiment with different recommendation algorithms.

Absence of Clear Interfaces: There is no well-defined interface or API layer for communication between different components or systems. This results in tight coupling and makes it challenging to integrate new features or replace components without impacting the entire system.
This Big Ball of Mud scenario in the machine learning architecture for retail product recommendations (RecSys) reduces the system’s flexibility, scalability, and maintainability. It becomes increasingly difficult to introduce new recommendation strategies, adapt to evolving business rules, or leverage advancements in machine learning techniques.
To mitigate this anti-pattern, modularization, separation of concerns, and adopting a simple 2x2 architecture of online vs offline environments with candidate retrieval vs ranking can be done.
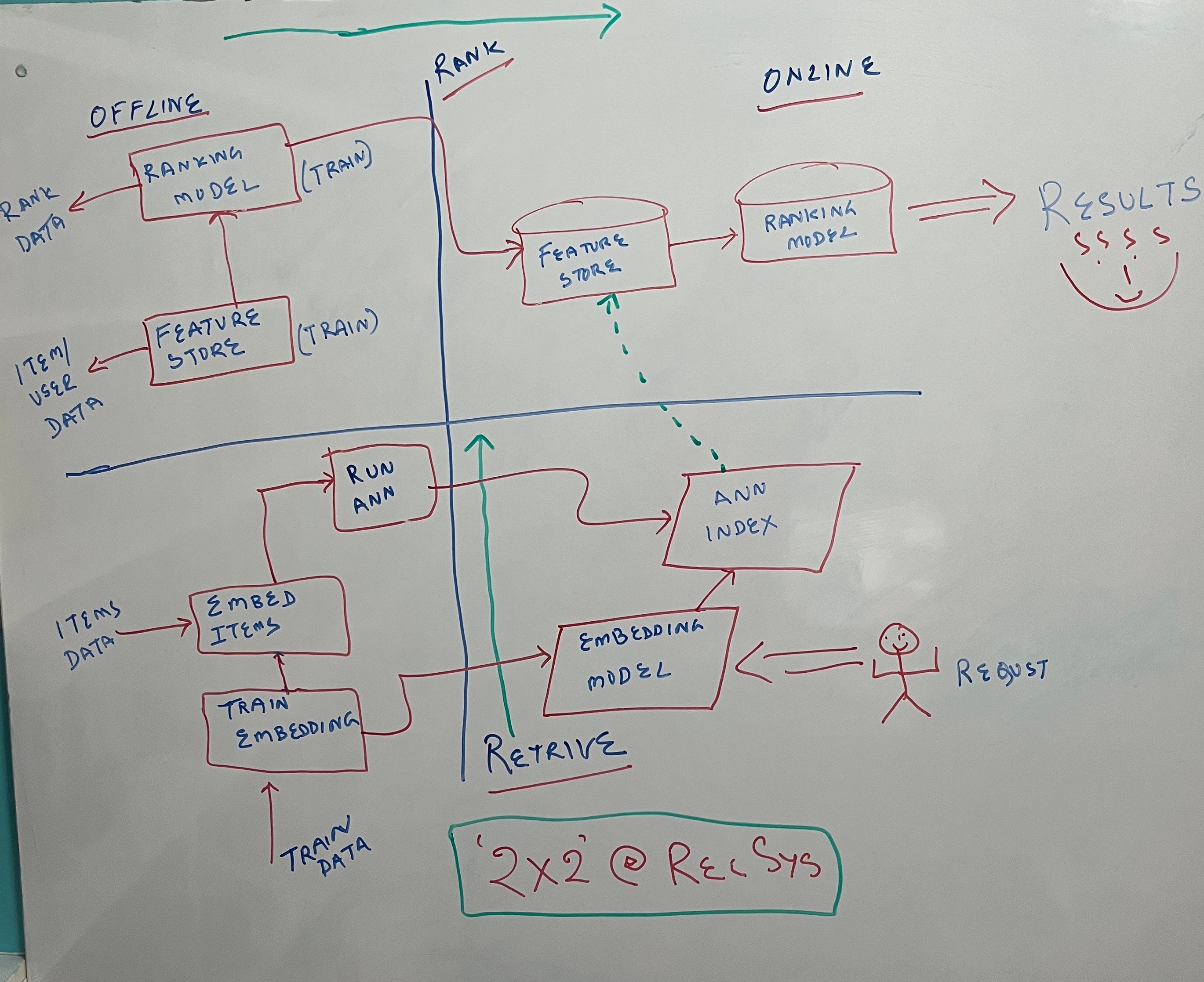
The offline environment will be batch based model training and creating embedding for catalogue items and also doing the calculations for the ANN index. To enable faster offline batch processing use of a “feature store” of items and users data.
The online environment is where the user can request the start of the RecSys flow. The approach is to convert the search to embedding and then for retrieval and ranking. The ranking finally showcases the options and can be a Logistics regression of click or a softmax over a catalogue of items using neural networks.
As shown in the diagram above,
Offline -> Data flows left to right to get you the Rank
Online system -> request flows bottom ups to get you the Retrieval
As you can see the results are displayed by the RecSys when the ranking is done post retrieval.
The lack of modularity is addressed as we have the 4 quads doing different things and a decoupled design focusing on retrieve and rank. Ad hoc data processing is not a pain as we have enabled the offline training using feature stores. The BAU business rules are totally separate and not considered here, as we will take in the items data into our feature store which would be already available offline.
So this is simple yet effective and not a mud of ball as this design pattern can now be thought of micro-services as well. In such a case, you can have a services call the retrieval and ranking from the pre-trained models using feature stores.
References:
Yan, Ziyou. (Jun 2021). System Design for Recommendations and Search. eugeneyan.com. https://eugeneyan.com/writing/system-design-for-discovery/.
And
You can read my other article. I recomend the below one specifically for you.
Click below:
What causes career stagnation in IT?

This is a long article, so grab and coffee and read on! Career stagnation in the IT industry is a serious silent challenge. In this article, I will try to share the views that I have gathered over the years by working in the IT industry and then changing tracks to the Analytics and startup sector to bring a contrasting summary. I am currently opening up…